This article describes annotation of images and creation of training models for Deep Learning segmentation in arivis Pro using the optional arivis AI toolkit
Summary
- Open the Deep Learning trainer from the Analysis menu
- Create and rename object classes as needed
- Use the brush tool to draw on the image the objects you wish to segment
- Use the brush tool for the background class to draw the background around the class objects
- Continue adding class and background objects until there are enough for a good training (at least 100, preferably more) that include the widest range of expectations for what an object might look like
- Click Train to start the training process
- When the training is complete, click Open in Pipeline to use the trained model for segmentation
Introduction
Image segmentation, the process of identifying objects from an image, has been around for as long as digital images. Usually, this process involves creating and using algorithms to classify pixels in an image and then using this classification to identify objects. Various algorithms exist to classify pixels, which often work fast and well but have several limitations regarding the types of images that can be analyzed, and often require a high level of knowledge and skill to apply successfully. whereas humans can usually be trained quickly to recognise objects from images. Deep Learning works by using human knowledge of what constitutes an object to train a model that a computer can use to interpret the image data and produce objects. The exact workings of how a DL network performs the classification are highly complex, but the process of creating a network and applying it to images is accessible to anyone with basic computer skills.
Since arivis Vision4D 3.6 it has been possible to run DL inference for segmentation. This inference can use pre-trained models created with apeer and other platforms that use ONNX models. This only requires that the Vision4D license include the Analysis module.
With Vision4D/arivis Pro 4.1 it is possible to train models directly in the application. This requires a license that includes the AI toolkit and also requires that the arivis Deep Learning package for GPU acceleration be installed.
Creating a new DL model
Accessing the DL Trainer and creating classes
Creating models is done in the Deep Learning Trainer panel. We can open this panel from the Analysis menu.
With the Deep Learning Training panel open we can define or rename the classes as we need them:
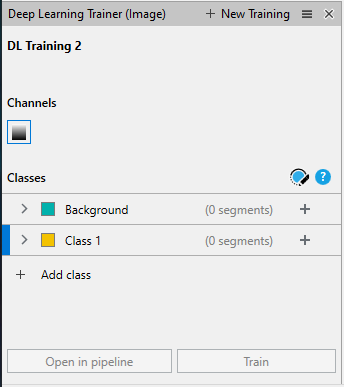
By default, there are 2 classes to start with a "Background" class and a "Class 1" object class. For a DL network we need to know both what the objects look like and what the background looks like. This allows us to annotate only portions of the image without needing to label every single class object on a plane. We can rename the object classes by double-clicking on the class name.
And we can add additional classes by clicking + Add Class.
Note that object classes cannot overlap, so if we want to be able to segment objects inside other objects it may be preferable to create multiple separate training for each individual object class.
Annotating objects
Creating a DL training involves providing an untrained network with a ground truth from which the network can learn. In the case of image segmentation, this involves providing examples of the types of objects we want to segment, and the background that the network should exclude. There can be several classes of objects, but they cannot overlap.
With the classes created, we can set about the task of annotating the ground truth segments. We can start by selecting a plane with both objects and background visible and using the brush tool to draw some examples of class segments.
We can carry on drawing segments as needed for regions of the image or the entire plane. Once we've finished drawing the object class segments we can add the background region that the network can use to learn. to do this, we select the background class and use the brush tool to draw the background as required.
Some important things to consider when drawing the object and background class segments:
- For an effectively trained network, it is important to include as wide a range of representative objects as possible. If all the class segments we provide are roughly the same size the network is likely to learn that only objects that fit within that size range should be included. If the objects we seek to segment can be round or have highly irregular shapes, both should be included in the ground truth.
- Defining what doesn't count as an object is just as important as defining what does. Background regions should include the same range of expected variety as the object class.
- We need to make sure that the background region does not include anything that might be included in the object class. If there are unannotated regions of the image that could contain class objects, these should be avoided.
- We don't need to account for every single pixel in the image, but we do need a representative sample of both background and class segments. The network learns best from a large sample of representative data. The more segments we provide as ground truth the more likely we are to obtain an effectively trained network. A minimum of 100 class objects is recommended, but more is better.
- DL can make inferences even from imperfect data, but for it to be successful at this task the training should include imperfect examples. If your dataset includes some abnormal planes with, for example, a higher level of noise of shading variations, these planes should be included in the training dataset.
Training the network
Once we have annotated a sufficient number of class and background segments we can train the network by clicking the Train button at the bottom of the panel.
The trainer will initialize and start by asking the user to verify the training parameters:
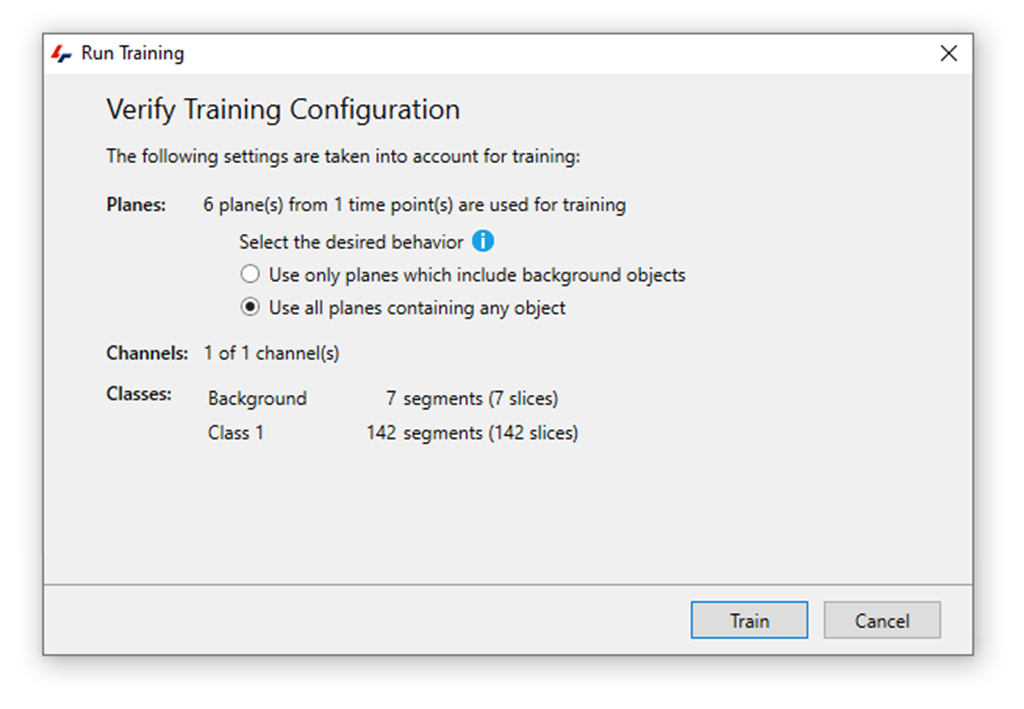
At this point, the software will show the total number of classes and objects in each class, and if there are only a few annotations for the objects class it will prompt you to return to the annotation task. In that case, if no further annotations are possible or if we just want to start with a small selection to get a preliminary result, we can proceed with the training or else return to providing ground truth annotations for better training.
If we want to proceed with the training, we can just press the Train button and, after a brief initialization process, the training will start.
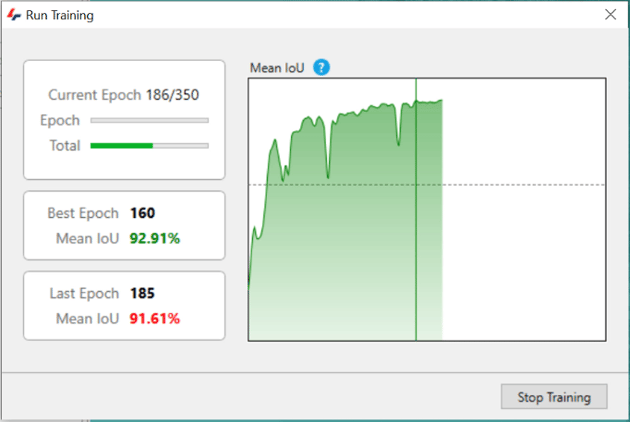
Note that the task of training the network can be very resource-intensive and time-consuming. It is generally best to allow for several hours in most cases, during which it is best not to rely on the computer, and especially the GPU, for any other tasks. Note that while the training is running it is not possible to use Vision4D.
When the training is complete, it results and error will appear in the training window:
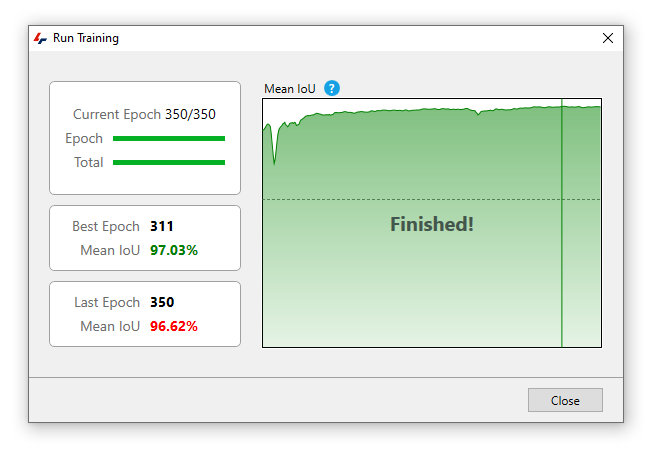
We can then use the trained network on our pipeline.
Using a DL training in a pipeline
Once trainings have been created, actually using them in a pipeline is just as easy as using any other pipeline operation, and the results of a DL segmentation can be used in a pipeline in exactly the same way as any other pipeline segments. This includes the ability to:
- Apply object modifications like splitting, dilating, or eroding
- Classify segmented objects based on any of the available object features, and filter out objects that don't meet any given criteria
- Establish Parent/Child relationships or measure distances between objects, including with other objects that were not created through DL
- Export object features and segments masks if needed
The simplest way to use a trained network is to create a new pipeline that uses this network immediately after training. At the bottom of the DL Trainer panel, once the training is complete we can click on Open in pipeline. The software will automatically open the analysis panel, create a new pipeline, add the Deep Learning Segmenter operation to the pipeline, and select the trained model for use with the operation.
With our trained model in the pipeline, we can use this segmentation operation and its output like any other pipeline segmentation operation.
Please see this other article one using Deep Learning in pipelines for more information on configuring such pipelines to DL models, including custom models created elsewhere, including ZEISS arivis Cloud.