This article explains the basic principle of segmentation for people who are new to imaging
What is segmentation?
In a nutshell, segmentation is the process by which software converts the pixels in the image, which are just intensity measurements, into objects that we can use to characterize certain features of the objects. Those features can include counting how many objects there are, their morphological properties (volume, surface area, sphericity, etc), intensity characteristics to measure signal expression, or more complex inter-object relationships (number of children, distance to the nearest neighbor, etc).
Segmentation is generally a 2 step process where the pixels in the image are first classified as belonging to either the background or object class, and then the actual segments are created by establishing the relationship between the neighboring pixels. The simplest and most common kind of segmentation is based on an intensity threshold, where pixels are classified according to their value being above or below a given threshold and then contiguous groups of object class pixels are identified as objects.
To better understand this process consider this very simple image:

Humans have no issue intuitively recognizing dozens of individual object, and biologists might even interpret these as nuclei, but software doesn't work like that. What the software has is pixels, which are essentially just intensity measurements:


As a fun exercise, you can try to download this image as a CSV, import it into Excel, and use conditional formatting rules to color the pixels so that they are black if they have an intensity of 0, and white if they have an intensity of 255.
From this map of intensity values, we can set up a simple rule to the effect that all pixels with an intensity above a certain threshold are part of the object class. Here we can see highlighted in red all the pixels that meet our rule (value greater than 50).

Once the rule is established to classify each pixel in the image we then identify contiguous groups of pixels within the class as objects:

By analysing the pixels in each group we can extract features of the object such as:
- Volume (total number of pixels multiplied by the image calibration)
- Surface Area (total number of exposed pixel on the outside of the group)
- Mean intensity (sum of every pixel intensity in the group divided by the total number of pixels)
- ...
Instance Vs Semantic Segmentation
As we can see from the example above, once the pixels have been classified into their various classes identifying objects is relatively easy. However, most objects in an image are not usually so conveniently resolved. In many cases, objects can appear to touch or even overlap.
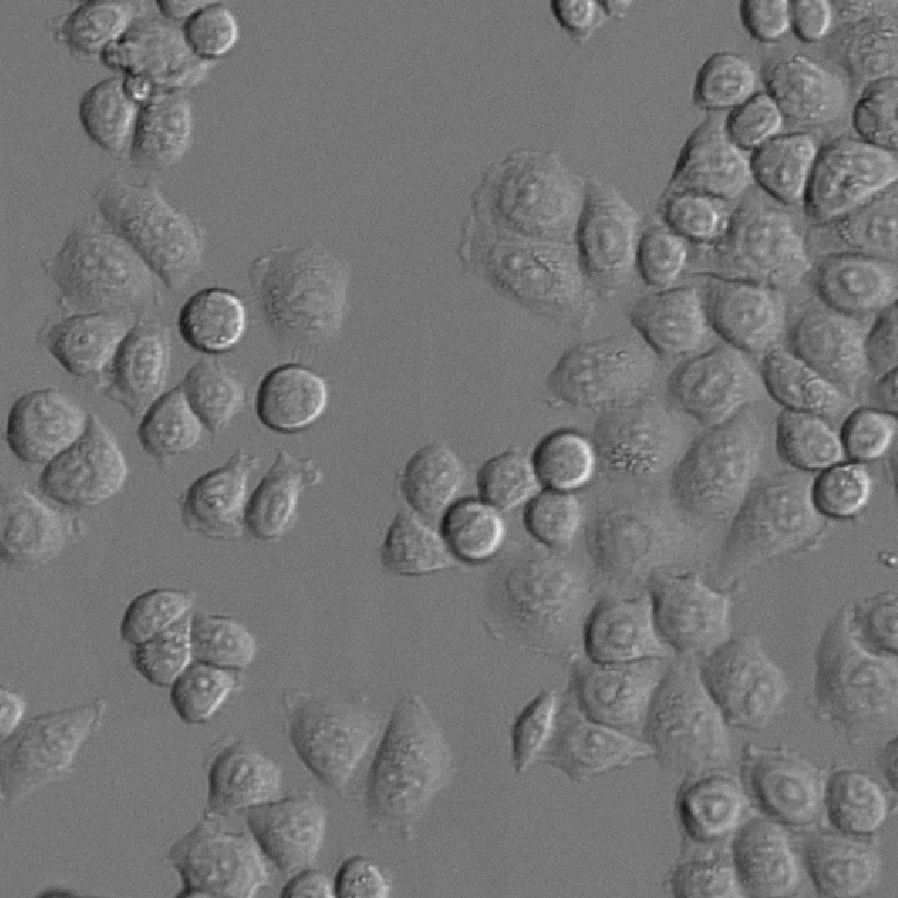
In such cases, a method that simply classifies pixels to identify contiguous groups would produce only one contiguous mass rather than discreet objects.

Such segmentation is known as semantic segmentation.
Separating this singular mass into individual objects is known as instance segmentation.

Various methods exist in arivis for both semantic & instance segmentation, using both traditional intensity based techniques and new ML and DL tool. Examples of Semantic segmentation in arivis Pro include:
- Threshold based segmenter
- Machine Learning segmenter (using a random forest pixel classifier)
- Deep Learning Segmenter using ONNX models
And instance segmentation tools include:
- Blob Finder
- Region Growing
- Watershed segmenter
- Membrane based segmenter
- Cellpose based segmenter
- Deep Learning segmenter using arivis Cloud Instance models
To find out more about using Deep Learning for instance segmentation, please check this article.